大家好,我是小焦。今天我们来看一看陕西省政府采购网(http://www.ccgp-shaanxi.gov.cn/)的数据怎么爬取?因为公司要看一看采购项目,挨个一个一个点的话比较麻烦。我们刚好可以用代码来自动帮我们完成数据的筛选,节省大量的时间。
提前声明一下,我写这个代码只是为了个人方便,读者切勿用作非法或者商业用途使用。
任务目标:
首先我们本次爬虫的任务是完成该网站的采购招标信息爬取,省去人工耗费的时间。快速筛选出我们的需要的指定信息。然后将招标信息的标题、链接、和时间找出来,并保存。
准备工具:
- python3
- chrom浏览器及dirver驱动
- mysql
- pyquery、selenium、等库的了解
思路:
当我们完成上述的准备工作之后就是研究目标网站的结构了。通过简单的点击查看等操作,我们发现这个网站是一个动态网站,对应的内容都是javascript来动态加载的,普通的requests肯定不能获取到随时变化的内容了。所以我们选择selenium工具来模仿人的点击操作,获取网页源码,然后提取出对应的信息了。
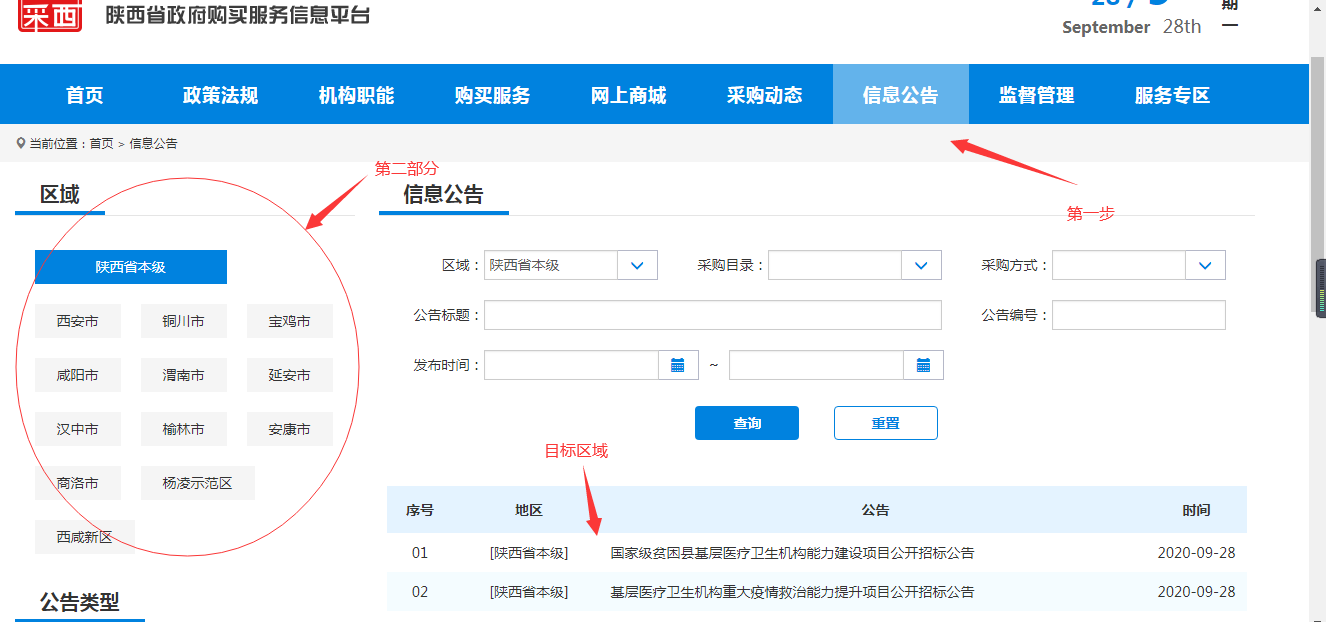
上述的页面就是我们要获取的页面。先是选择信息公告,然后选择对应的区域,我们的目标区域内容是动态加载的。它就是我们最终目标。由于招标文件太多,也不好排版,我们只需拿到想要的招标题目、链接、日期就可以了。
由于我们要获取指定的市区招标文件,我们要借助selenium模仿浏览器点击操作,点击我们想要的城市,然后目标区域的内容会自动变化,我们在进行区域的信息筛选就能达到我们的目的了。
好的,不多说了,大家看看代码吧。
# 2020.9.13日
# 本次爬虫主要是实现陕西政府采购网的爬虫
# 该爬虫以技术交流为准,切勿用于任何非法用途,后果自负
# 我的个人博客:https://jiaokangyang.com
from selenium import webdriver
import pymysql
import time
from pyquery import PyQuery as pq
from docx import *
# 由于该网站是javascript来异步加载的,而且requests不能正常获取,这里我们使用selenium爬取
url = 'http://ccgp-shaanxi.gov.cn/notice/list.do?noticetype=3&province=province'
shuru = input('请输入要爬取的区域名称,确保在网站的范围内:')
shuru2 = input('请输入上述城市中要筛选的区域名:\n(如不需要筛选则直接敲击回车键开始抓取)\n')
# 创建一个空文档,用于后面的文档保存
document = Document()
# 链接数据库
conn = pymysql.connect(host='localhost',user='root',password='123456',port=3306,database='shanxi')
# 获取游标,后面进行sql语句的执行
cursor = conn.cursor()
# 如果表不存在则创建一个名为shuju的表。这里切记mysql中的列名字不需要加双引号。
cursor.execute("create table if not exists shuju(id int not null auto_increment primary key,title varchar(50) not null,url varchar(100) not null,riqi varchar(20) not null);")
# 打开谷歌浏览器
brower = webdriver.Chrome()
# 打开采购信息的网页
brower.get(url)
# 打开网页后,点击对应城市的标签,然后异步加载的内容进行加载。
if shuru != '':
brower.find_element_by_link_text(shuru).click()
# 这块由于代码自动操作太快,有时出现内容没更新的情况,所以我们等待两秒
time.sleep(2)
# 该函数完成单页内容的采集输出
def get_onepage(html):
html = pq(html)
a = '[' + shuru2 + ']'
lists = html('.list-box table tbody tr').items()
for list in lists:
if shuru2 != '':
b = list('td:nth-child(2)').text() # 使用pyquery的伪类用法查找第二个元素内的名字
if b == a: # 对比分析,如果和我们输入的区域名字相同,则打印出来
title = list('td a ').text()
url = list('td a ').attr('href')
date = list('td:last-child').text()
# 如需写入word,请将getmysql方法换成get_word即可
getmysql(title,url,date)
else:
title = list('td a ').text()
url = list('td a ').attr('href')
date = list('td:last-child').text()
getmysql(title, url, date)
# 上面完成单页信息的采集,现在进行前五页的信息采集。
def get_page():
for i in range(1,6):
print('开始抓取第%s页'%i)
# 由于第一页不用点击操作我们从第二页开始进行点击操作
if i > 1:
brower.find_element_by_link_text(str(i)).click()
# 这块停顿两秒,让页面内容顺利加载出来
time.sleep(2)
html = brower.page_source
get_onepage(html)
print('抓取第%s页完毕'%i)
brower.close()
# 该函数将获取到的内容写入到word文件中
def get_word(title,url,date):
document.add_paragraph(title)
document.add_paragraph('网址:' + url)
document.add_paragraph(date + '\n')
# 此函数将爬到的数据最近写到word中
def execute():
# 给文档添加标题
header = '{}{}招标项目清单'.format(shuru,shuru2)
document.add_heading(header,level=0)
# 运行爬虫程序
get_page()
# 将爬到的数据保存
document.save('{}{}招标清单.docx'.format(shuru,shuru2))
# 该函数完成将数据写入mysql的操作
def getmysql(title,url,date):
sql = "insert into shuju(title,url,riqi) values('%s','%s','%s')" %(title, url, date)
# 执行sql语句
cursor.execute(sql)
# 执行数据库写入操作
def main():
# 执行get_page函数,将所有的数据写入到数据库
print('开始执行爬虫')
get_page()
print('爬虫执行完毕,并关掉数据库')
# 提交数据,关闭数据库
conn.commit()
conn.close()
main()上述代码看似混乱,其实非常简单,我只要是写了一个单页的采集函数,然后就再写了一个前五页的函数,其次就是写入word的函数和数据库的。也是边学边摸索。
效果展示:
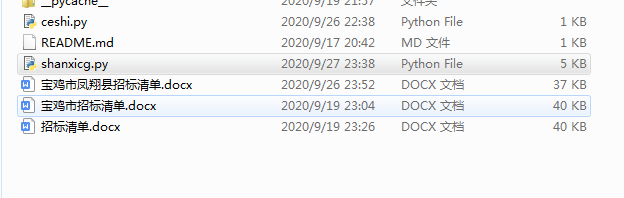
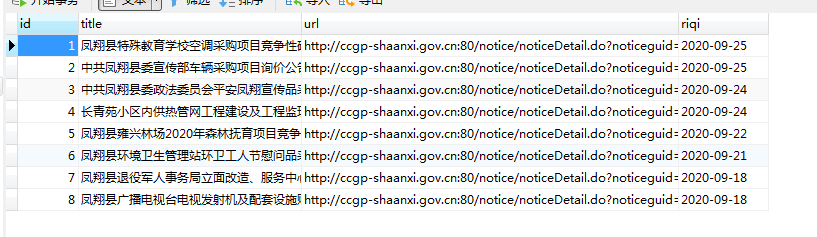
github地址:https://github.com/zhanjiuyou/shanxicg.git
声明:代码虽烂,但请读者切勿用作非法用途,后果自负








评论抢沙发