大家好,我是小焦。端午节马上到了也是提前祝大家节日快乐。今天我给大家分享的是如何用python爬虫获取天猫商家的联系方式。相信这对搞电商服务的朋友肯定有用,更多的客户意味着更多的成交机会。传统的推广都是自己一个一个在旺旺上面一个一个找客户,费时费力不说还经常被封号。那么小焦给大家带来的就是用程序批量找到对应商家联系方式。
准备工作
- 安装chrome谷歌浏览器
- 下载启拉助手压缩包(地址:https://www.qilacps.com/),并注册启拉账号。
- 在阿里的网站下载你自己chrome浏览器对应版本的chromedriver驱动程序,并放到python的script文件夹下,怎么查看版本自己百度(地址:http://npm.taobao.org/mirrors/chromedriver/)
- 将启拉助手下载后解压,得到的文件夹拖到谷歌浏览器的安装目录,有一个版本号的文件夹,放到它下面即可。
做完上面的工作,我们的准备步骤已经完成。现在小焦给大伙说说为啥这么做。下载安装谷歌浏览器和驱动肯定必须的,我们python程序就是模仿控制浏览器来抓取数据的。重中之重就是这个启拉助手了,我们要借助这个浏览器插件获取我们需要的信息。这块不详细说了,下面我们会分来来说。
模块介绍
我们主要分为5个模块来写程序的。淘宝登录、启拉助手登录、获取商家列表、获取联系方式、主程序。登录这块不用说你也懂,淘宝不登录的话一直提示让你登录,超级烦。启拉助手也必须登录不然不能使用功能,每天免费获取100个。下面我们是将这些模块整体写了一个类方便调用。先说模块,然后其中还有几个重要反爬说说一下。
淘宝登录:这块我用的是最简单的扫码登录方式,利用chrome驱动打开页面,然后我们自己手动扫码方式登录。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import json
import re
class phone():
def __init__(self,key,qilaname,qilapassword,page):
# 设置为chrome浏览器,并确定url,key为要搜索的内容
option = webdriver.ChromeOptions()
# 加载启拉的插件
option.add_argument("load-extension=qila_helper_brower_plugin")
option.add_experimental_option("excludeSwitches", ["enable-automation"])
option.add_experimental_option('useAutomationExtension', False)
# 设置加载模式,当出现我们指定元素页面停止加载
capa = DesiredCapabilities.CHROME
capa['pageLoadStrategy'] = "none"
self.url = 'https://www.tmall.com/'
self.brower = webdriver.Chrome(chrome_options=option,desired_capabilities=capa)
# 设置最长等待时间
self.wait = WebDriverWait(self.brower,30)
# 搜索的关键字
self.key = key
# 启拉插件的账号密码
self.qilaname = qilaname
self.qilapassword = qilapassword
# 用来存放爬取到的所有url
self.urls = []
# 设置爬取的页数
self.page = page
# 登录天猫
def login(self):
self.brower.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
self.brower.get('https://login.tmall.com/')
print('请在30秒内扫码登录')
try:
self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="sn-container"]/p/span')))
print('登录成功')
return True
except:
print('登录失败')
return False启拉登录:方法一样,打开启拉官网,自动填写我们的账号密码然后登录
# 登录启拉助手
def qilalogin(self,):
self.brower.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
self.brower.get('https://www.qilacps.com/login')
# 输入账号
self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="el-form-item is-error is-required"]//input'))).send_keys(self.qilaname)
# 输入密码
self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="el-form-item is-required"]//input'))).send_keys(self.qilapassword)
# 点击登录按钮
self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="login-container"]//button'))).click()
time.sleep(1)获取商家列表:这块主要是模拟正常的搜索流程,输入我们的关键字,然后点击搜索按钮,然后点击那个店铺按钮,就会得到商家列表,由于启拉助手只在商品详情页出现,所以我们要获取每个商家的其中一个商品页。
# 根据输入内容查找并返回所有商品详情页的URL
def seek(self):
# 加入cookies
# if os.path.exists('cookies.txt'):
# with open('cookies.txt','r') as f:
# cookie = f.read()
# f.close()
# cookies = json.loads(cookie)
# else:
# print('没有cookie,请生成cookie后再运行')
# return False
# self.brower.get(self.url)
# for cookie in cookies:
# self.brower.add_cookie(cookie)
# 登录启拉账号
self.qilalogin()
if self.login():
self.brower.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
self.brower.get(self.url)
# 打开天猫主页,输入key点击搜索按钮
self.wait.until(EC.presence_of_element_located((By.NAME,'q'))).send_keys(self.key)
self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="mallSearch-input clearfix"]/button'))).click()
# 停顿两秒
time.sleep(2)
# 点击店铺按钮
self.wait.until(EC.presence_of_element_located((By.XPATH,"//div[@class='filter clearfix']/a[@class='fType-w ']"))).click()
# 获取总页数
page = self.wait.until(EC.presence_of_element_located((By.XPATH,"//div[@class='ui-page-wrap']/b[@class='ui-page-skip']/form"))).text
pages = re.findall(r"共(.*?)页",page)
pages = int(pages[0])
print('搜索到结果共%s页'%pages)
if self.page > pages:
self.page = pages
for i in range(1,int(self.page)+1):
print('抓取第%s页'%i)
# 获取第一页时不用点击下一页
if i > 1:
time.sleep(2)
self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'ui-page-next'))).click()
# 这个是商品页获取url
# links = self.brower.find_elements_by_xpath('//div[@class="view grid-nosku "]//p[@class="productTitle"]/a')
# 下面这个是通过搜索店铺获取商品url
links = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="shopBox shopBox-expand j_ShopBox"]/div[2]/div/div[1]/p[2]/a')))
for link in links:
url = link.get_attribute('href')
print(url)
self.urls.append(url)
# self.wait.until(EC.presence_of_element_located((By.CLASS_NAME,'ui-page-next'))).click()
time.sleep(2)
else:
print('登录失败')
return False详情页信息获取:这里也是我们的关键一步,当我们已经拿到所有商家的商品页后,就逐一访问,利用助手获取他们的信息。平时我们都是手动点那个电话按钮来获取信息,现在则是浏览器自动点击按钮获取。
# 获取商品详情页URL
def getphone(self,url):
self.brower.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"
""
})
self.brower.get(url)
# 点击电话按钮
# shopname = self.brower.find_element_by_xpath('//div[@id="shopExtra"]/div/a/strong').text
shopname = self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@id="shopExtra"]/div/a/strong'))).text
b = self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@id="qila_helper_container"]/div[@id="qila_helper_nav"]/div[@class="ivu-col ivu-col-span-1"]//button')))
if b:
self.brower.execute_script('window.stop();')
time.sleep(1)
b.click()
else:
self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@id="qila_helper_container"]/div[@id="qila_helper_nav"]/div[@class="ivu-col ivu-col-span-1"]//button'))).click()
print('点击成功')
time.sleep(1)
# 获取姓名
username = self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="view-phone-data-container v-transfer-dom"]/div[@class="ivu-modal-wrap"]/div/div/div[@class="ivu-modal-body"]/div/div/p[1]/span[2]'))).text
# 获取邮箱
email = self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="view-phone-data-container v-transfer-dom"]/div[@class="ivu-modal-wrap"]/div/div/div[@class="ivu-modal-body"]/div/div/p[2]/span[2]'))).text
# 获取电话
phone = self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="view-phone-data-container v-transfer-dom"]/div[@class="ivu-modal-wrap"]/div/div/div[@class="ivu-modal-body"]/div/div/p[3]/span[2]'))).text
print('店铺名:%s'%shopname)
print('姓名:%s\n邮箱:%s\n电话:%s\n'%(username,email,phone))
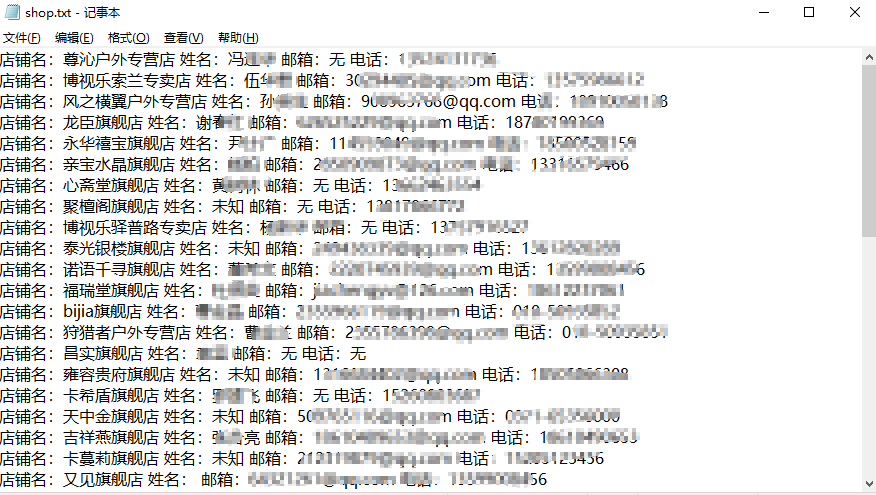
return shopname,username,email,phone主程序:当我们每个功能实现后,就是按照正常流程运行,然后将获取到的信息保存到一个txt文件中了
#总的调度函数
def run(self):
self.seek()
try:
with open('shop.txt', 'a') as f:
for i in self.urls:
time.sleep(2)
shopname,username,email,phone = self.getphone(i)
f.write('店铺名:%s 姓名:%s 邮箱:%s 电话:%s\n' %(shopname,username, email, phone))
f.close()
self.brower.close()
except:
f.close()
self.brower.close()使用方法:上面我们是将所得的方法都写在一个phone的类中的,我们只需实例化这个类,然后运行它就行。下面是爬取古玩产品的商家,获取前四页内容,一个页面是20个商家信息。
# 爬取前四页
a = phone('古玩','启拉账号','启拉密码',4)
a.run()效果展示
- 反爬;由于chrome浏览器在自动调入的时候会在头部加入webdriver字样,所以我们在每次访问新页面的时候都要取消这个标识,所以我在每次调用get方法前面都加入了一串代码,大家自己看
- 加载:由于我们只需要页面中的几个关键信息就行,加载多余的是浪费,所以在获取到有用的信息时就停止了页面下载。具体代码看最顶部init方法,在获取详情页方法中,当启拉助手加载完毕后我们立马阻止了页面继续加载,只要能够正常点击电话按钮就行。
完整代码:https://github.com/zhanjiuyou/tianmao_phone
(记得将助手解压后的文件夹在放到程序的同级目录)








评论抢沙发