您好,我是小焦,前几天我给大家分享了糗事百科的段子爬虫。也是作为爬虫新手的一个小练习吧。今天我又完成了妹子图网站的图片爬虫,也是作为练习爬虫技术来做的。通过这两天的练习,我已经认识到实战有多重要。古人常说“好记性不如烂笔头”’,今天我也给大家分享我的经验,好记性真的不如一次实战重要,因为我在写代码过程中,深深的发现我之前看的好多知识想不起来,甚至不会用。
这里也就不多说了,总之一句话,要想有好的技术就一定要实战,实战,再实战。
进入我们今天的正题,妹子图网站(https://mzitu.com),从名字就可以看到里面是众多美女的图片,这里就不放了,尺度有点大。毕竟我们是搞技术的。该网站也是非常简单,是一个静态网站,就是页面比较多而已。我们今天的目标就是把上面的图片爬取下来,每组图片创建自己的文件夹,然后各自下载。
先来看看我运行程序后,爬取的结果(请自觉忽视里面内容):

准备工作:
- python3
- requests库
- os库
- threading库
- pyquery库
写爬虫之前,我们肯定要了解以上几个库的应用。其中os和threading我是边学边实战的,之前也没有接触过,大家不懂得先下去了解一下这个两个的库的应用方法。
网站分析
在我们进行爬虫代码之前,首先是要分析 目标网站的结构目录。经过分析,我们发现此网站是一个纯静态网站,非常简单,就是组图的这块不符合人意。一个页面只有一个图片。我们先来看看首页的源代码吧
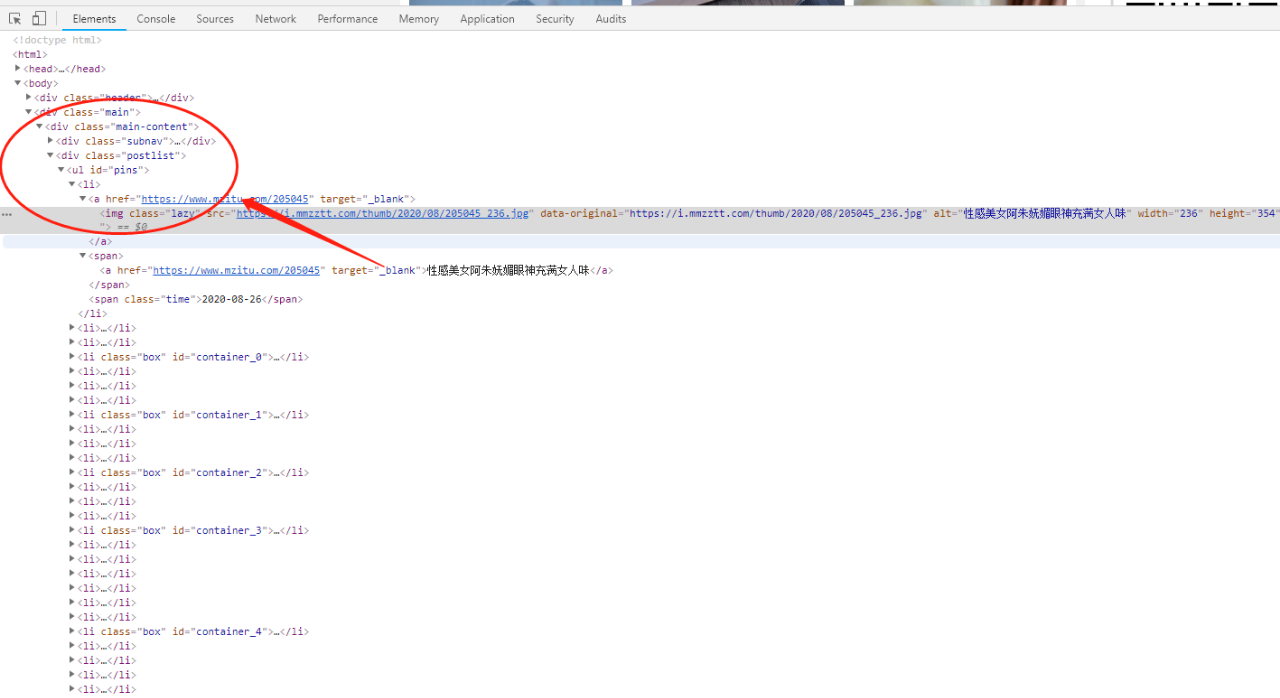
图片可能比较小看不清。但是我们可以看到是非常整齐的li标签。每个标签里面则有着组图的名称和详情链接。分析完网页,小焦简单介绍下我的爬取思路。首先我是为了方便,将每个功能进行函数的封装。说实话我之前写爬虫基本不用函数,现在发现写很多的函数非常方便调取。
下面代码中,我用requests库写了一个下载网页代码的函数,页面抓取这块写了一个,组图详情图片这块写了一个函数。不同的功能区分开,非常方便调用。其次就是最好的多线程的应用,这个也是我第一次使用多线程爬取东西,感觉效率非常的高。为了节约资源,我设置了最大线程数,使用的是笨办法,网上很多的类的方法,由于我对python中的类还没有多深的理解,所以就没给自己挖坑,等技术熟练了再研究。好了,直接看代码吧。每个步骤的解释我写的很清楚。
# 2020年8月27日
# 本次爬虫主要任务是爬取妹子图网站的图片,此代码只用于python技术的研究探讨,不做其他用途。
# 郑重申明:切勿用于非法用途,后果自负。由于此网站图片尺度较大,读者只需关注本代码研究代码本身,切勿关注其内容,切勿非法传播。如有问题请及时联系我反馈谢谢。
# 个人博客:https://jiaokangyang.com
import requests
import threading
from pyquery import PyQuery as py
import time
import os
# 这里我们先创建一个字典,将对应目录的缩写设置好便于后面调用,随便写了几个,要想更多自行添加
mulu = {
'日本':'japan',
'台湾':'taiwan',
'清纯':'mm',
'性感':'xinggan',
'最热':'hot'
}
s = input('请输入你要爬取的分类名称\n目前有以下分类可供爬取:日本、台湾、清纯、性感、最热。\n')
if s not in mulu:
s = input('输入内容不在爬取范围请重新输入:')
# 创建函数爬取页面源码并输出
def down_page(url):
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4208.400',
}
r = requests.get(url,headers=headers)
return r.text
# 获取每个套图的页面列表,并下载文件
def get_pic_list(html):
pics = py(html)
taotu_lists = pics('#pins li ').items() # 将获取到的内容
for list in taotu_lists:
link = list('a').attr('href')
text = list('span a').text()
get_pic(link,text)
# 获取每个套图中的前十个图片
def get_pic(link,text): # 这里传递两个参数,一是获取图片,二是将获取到的图片放到对应的文件夹下面
for i in range(1,11): # 由于此网站每个套图页面只有一张图片,而且数量较多,所以我们默认抓取前10张
# 这块将每个图片的页码加到后面组成新的链接
url = link + '/' + str(i)
html = down_page(url) # 用我们写得第一个函数获取获取网页的源码
pic = py(html)
pic_link = pic('.main-image p a img ').attr('src')
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4208.400',
'referer':'https://www.mzitu.com',
}
create_dir('pic/{}'.format(text)) # 创建套图的文件夹
r = requests.get(pic_link,headers=headers)
with open('pic/{}/{}'.format(text,str(i)+'.jpg'),'wb') as f:
f.write(r.content)
time.sleep(1)
# 在系统桌面创建目录
def create_dir(name):
if not os.path.exists(name):
os.makedirs(name)
# 为了便于后边多线程的调用,这里将执行的操作进行函数封装
def execute(url):
html = down_page(url)
get_pic_list(html)
# 主函数,整体程序运行
def main():
create_dir('pic')
pages = [i for i in range(1,20)] # 将前5页的页码写到列表里面,如需获取更多自行更改
threads = [] # 构建多线程池子,控制在5个线程内
while len(pages)>0: # 确定有页面可爬
for thread in threads:
if not thread.is_alive(): #判断线程是否运行,没有运行则从列表中移除
threads.remove(thread)
while len(threads)<5 and len(pages)>0: #最大线程控制在5个
cur_page = pages.pop(0) # 正常运行的话,先从发页面列表中吧第一个移除掉
url = 'https://www.mzitu.com/{}/page/{}'.format(mulu[s],cur_page)
print(url)
thread = threading.Thread(target=execute,args=(url,)) # 多线程运行execute函数
thread.start() # 启动多线程
print('同时正在下载{}页'.format(cur_page))
threads.append(thread)
if __name__ == '__main__':
main()上面的代码就给大家分享到这,有不懂得可以留言。个人建议不懂得先自己多看代码,分析思路哦。学会自己了解其中含义才是属于自己的知识。下面是抓取到的结果部分内容。也再次申明,本文以探讨python技术为题,坚决遵守中国法律。也请读者不要用此代码将抓取到的图片用于非法用途,后果自负。

源码地址:https://github.com/zhanjiuyou/mzitu.git








评论1