近日由于博主本人学习上的规划,决定后期一直朝爬虫方向。作为一名菜鸟选手只能从基础学起。之前虽然看了很多的书,发展真正学到的东西寥寥无几,关键还是在于运用和对库的了解程度。
好了废话不多说了,来看看今天的这个小爬虫吧,主要功能是输入搜索关键字,然后将结果的前十位给展现出来
工具
- python3
- urllib库
- pyquery库
其实整体思路非常简单,先分析网页结构,从观察网页源码,我们发现京东的页面加载是直接将HTML源码加载过来的,销量的数据是用JavaScript加载的。我们今天只需拿到商品的排行就行,置于它到底是怎么排,我们不管。
第一步
第一步我们随便搜索一个商品,观察它的顶部链接,这个靠经验,有的是在request里面找,像京东的链接我们直接在最上面的URL上就能看出端倪。
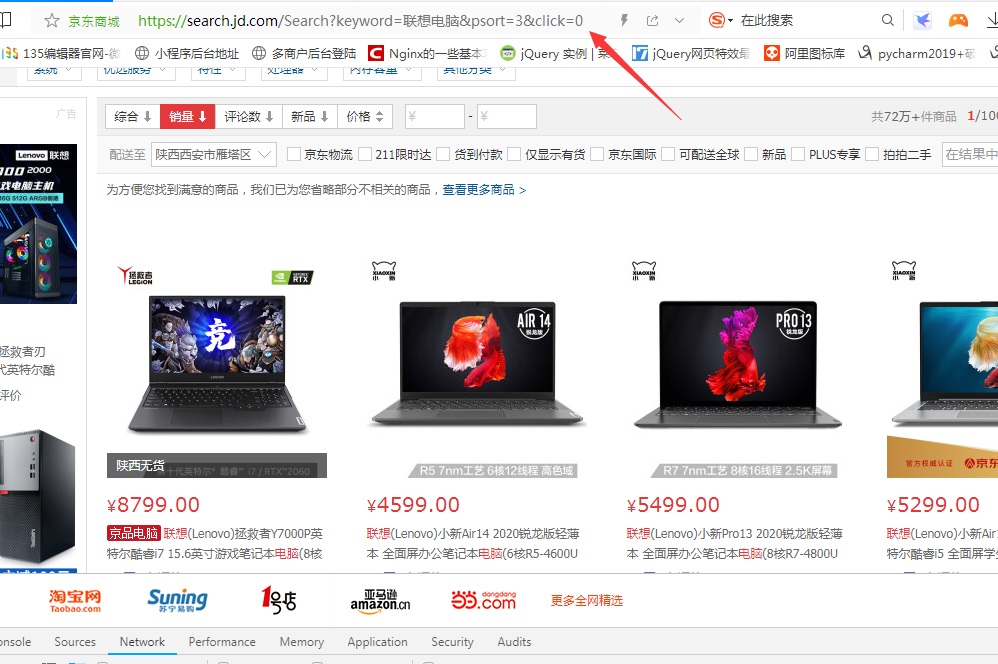
从上面链接中大家已经看到,我搜索的是联想电脑,然后URL中keyword部分就是我搜索的关键字。然后后面还有一个psort的关键字,首先我不认识这个单词,所以我先进行了几个测试,就是在销量和价格这些随便点了一下,发现它代表的数字对应的就是上面的筛选条件。
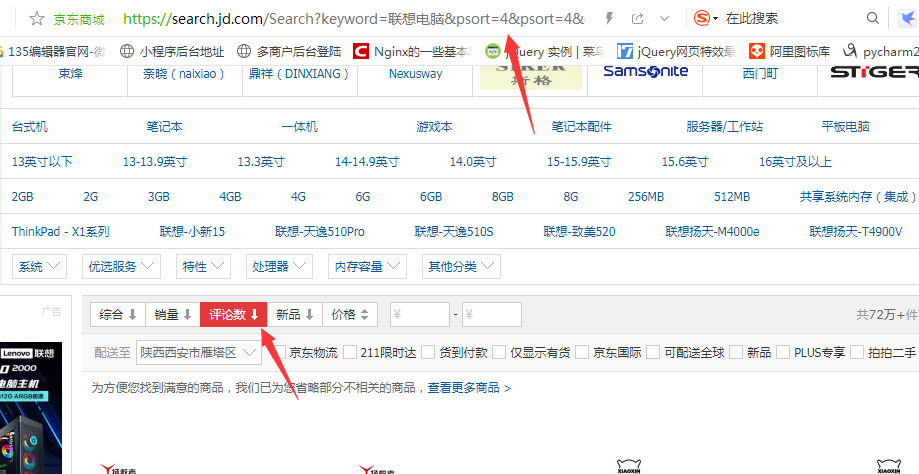
通过变化我们发现筛选条件不同,后面的数字则不同。所以我们就可以通过组合keyword和psort两个关键参数修改链接。好了不多说,直接上代码吧,下面是我简单写的小代码,中文式命名法,大家应该更好懂一些,哈哈。英语我才最近慢慢学着。
#京东商品销量排行 2020.7.21
#我的个人网站:jiaokangyang.com
import urllib.request
import urllib.parse
from pyquery import PyQuery as pq
#转换编码并将链接中字符替换掉
shuru=input('此程序为查询京东商品排行!\n请输入要查询的关键字:\n')
shuru=urllib.parse.quote(shuru)
#选择搜索结果的排序方式
guize=input('请选择结果排序方式用数字0~5代表:\n0代表综合,1代表价格由高到低,2代表价格由低到高,3代表销量,4代表评价数,5代表新品:\n')
guize=int(guize)
if guize == 0:
psort = ''
elif guize == 1:
psort = '&psort=1'
elif guize == 2:
psort = '&psort=2'
elif guize == 3:
psort = '&psort=3'
elif guize == 4:
psort = '&psort=4'
elif guize == 5:
psort = '&psort=5'
print(psort)
headers = {
'user-agent':' Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
}
#链接中psort为商品排行条件,3代表销量,4代表评论数,5代表新品,2代表价格升序,1代表价格降序,综合则没有此参数
url="https://search.jd.com/Search?keyword="+shuru+"&wq="+shuru+psort+"&click=0"
print('查询链接为:%s'%(url))
response=urllib.request.Request(url,headers=headers)
response=urllib.request.urlopen(response)
#上述步骤已经拿到单个网页的源码,后面则进行分析提取有用数据。
#用pyquery库对源码处理,然后利用CSS提取所需的信息
res=pq(response.read().decode('utf-8'))
lis=res('.gl-warp.clearfix .gl-i-wrap').items()
i=1
for li in lis:
ming=li('.p-name em').text()
jia=li('.p-price strong i').text()
print("第 %d 名\n%s"%(i,ming))
print('价格:¥%s\n\n'%(jia))
i=i+1
if i==11:
break
input('输入任意字符退出')上面代码中,我先设置了两个变量,为了可以自行输入关键字并确定筛选条件,其次返回源代码,利用pyquery库,对源码中的数据进行筛选,然后输出打印。功能也是非常的简单,后期随着我的学习,我会逐步增加功能,将拿到的数据写入数据库中。当然现在还不是很熟练。一会慢慢再谈,由于我后期主要学习方向是爬虫,如果有喜欢爬虫的朋友可以一起交流共勉。









评论抢沙发