上次简单说了scrapy框架的基本内容,我也是一边学一边整理。本想着利用这个框架把婚礼纪上面的商家信息重新抓取一遍,突然发现婚礼纪页面采用的是异步加载。之前的代码我是自己写的没有使用框架,是用最基本的抓包原理来操作写的,想完成什么步骤我直接自己写方法来完成的。
而使用框架后,发现有很多限制。它不是你想怎么来就怎么来的,也没有那么完美的事,必须遵循框架的规则。而我暂时这个框架还没学到动态网页工具这块,婚礼纪的下一页是用JS来完成的,所以用CSS方法不能直接完成。那么今天先来说一说静态网页的抓取把。
静态网页抓取
静态网站相对于动态网站来说比较容易,因为我们所有的操作直接可以分析它的html网页代码就可以完成。
今天就来演示一下http://quotes.toscrape.com/,这个站点的抓取把,这个也是老崔书中的案例,我也自己将代码自己分析整理了一边,代码很短。今天主要以笔记形式分析一下他写的代码。下面是本次要抓取的网页首页图
确立目标、创建项目、编写代码
这个网站主要是一些名人名言,我们本次要抓取的内容有作者、标签、以及语句内容。
#首先就是创建项目,
#我们进入到任意目录下创建本次项目,起名为tutorial,在命令行输入如下
scrapy startproject tutorial上次以及说了scrapy的目录了,就不多说,这次我们要操作的目录只有两个,分别是items.py和spiders。items是保存数据的容器,使用方法和字典类似,spiders目录用来存放爬虫程序的。
items.py中,我们需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。上面我们确立了三个要抓取的内容,然后我们下面则定义三个字段
import scrapy
class QuoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#定义 内容、作者、标签三个字段
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()三个要抓取存放的字段我们已经定义好,随后就是spider的编写,在写它之前我们肯定是要先分析目标网页。同过F12查看网页源码我们发现要抓取的内容都包含在class为quote的区块里面,分别是text,author,tags。
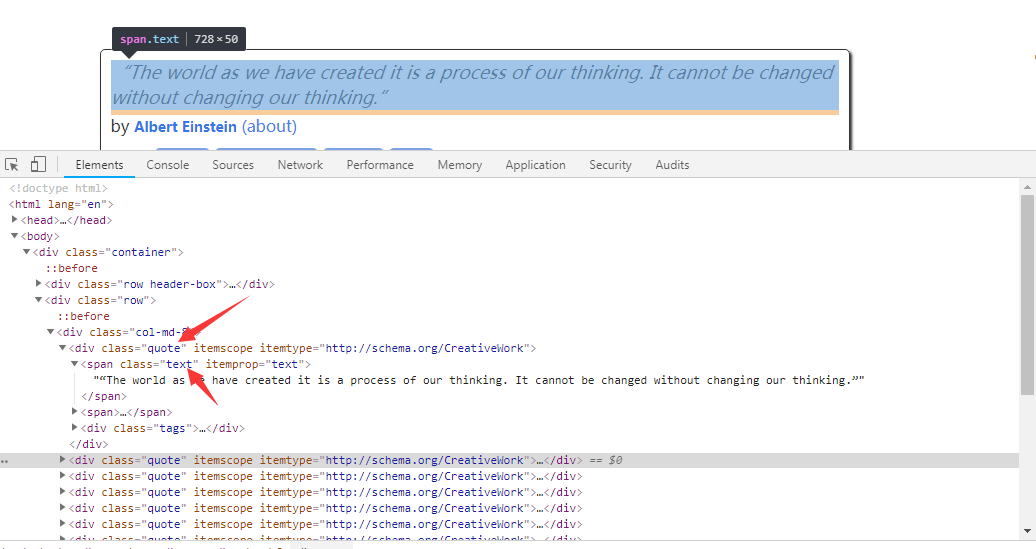
我们提取内容可以通过CSS或者xpath方式,这里使用CSS来提取。我们先创建spider然后编写代码如下。
#创建spider,名为quote,后面则是目标网址
scrapy genspider quotes quotes.toscrape.com
#代码如下,每行的作用我解释如下
import scrapy
from tutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
#spider我们定义的爬虫名字
name = 'quotes'
#domains的作用是我们后期爬取的链接都必须在它的域名之下
allowed_domains = ['quotes.toscrape.com']
#第一个url链接
start_urls = ['http://quotes.toscrape.com/']
#parse是scrapy的默认回调函数,我们先根据上面分析的class,然后利用css进行抓取。
# 然后将对应的数据赋值给对应的字段,extract主要是读取其中内容,因为语句和作者只有一
#个所以我们只需获取第一个值,则使用extract_first(),而标签有多个则全部获取
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
#上述利用循环我们抓取到了单页的所有内容,我们还要抓取下一页,
#所以找到下一页按钮的class,然后获取按钮的href值,由于它写的是相对路径,我们用urljoin方法进行url拼接
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url,callback=self.parse)最后则是callback回调函数继续调用parse进行抓取,一直循环。直到不能抓取。
执行项目
代码写完后就是运行项目进行抓取
#执行爬虫项目
scrapy crawl quotes #quotes则是我们刚才的爬虫名称
通过上述代码,我们只是展示爬取结果,我们当然还要保存数据,数据库这我还没搞懂,而它本身自带了json,xml,csv,等格式的输出。我们只需在后面加上-o参数+文件名即可
#输出json格式
scrapy crawl quotes -o quotes.json
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
#等等,格式很多,这个下去自己摸索今天的演示到此结束,基本上就把项目过了一边,其实主要分为两部分,第一就是我们确定要好抓取什么内容,并定义好对应的字段。第二就是spider的代码,写的也不是很详细,不懂的留言或者百度。或者入群交流谢谢。









评论抢沙发